-
trochu jsem missnul mark s tim, co šmíd chce, vůbec nezmínil Key value, typy NoSQL kromě XML a JSON, Multi, ani cap theorem
-
uspořádané úložiště dat
- umožňuje data ukládat, vyhledávat, upravovat, mazat, bezpečně spravovat
- Create, Read, Update, Delete - CRUD zkratka - důležité
-
nemusí být digitální, může to být sešit s tabulkou, několik šanonů
-
databázový stroj - software, který vytváří tabulku
-
bez databází - by programy ztráceli uživatele po vypnutí, neuměla ukládat objednávky, neměla žádnou historii akcí
-
nejjednoduší software - poznámkový blok
- excel to pak parsne, zeptá se na oddělovač
Typy elektronických databází
Key value
-
používá klíč (například jméno uživatele) a hodnotu (například jejich bio)
-
každý klíč je unikátní
-
na stejném principu funguje C# dictionary
-
příšerně rychlý (může být pod milisekundou na get)
-
v praxi bývají používané jako cache vedle jiné databázové struktury s lepší organizací, jako SQL
-
software
- redis
- memcached
- etcd
Redis - jednoduchý příklad
SET uzivatel:2 "martin"- nastaví klíč uživatel:2 na hodnotu martinGET uzivatel:2- navrátí martin
| KEY | VALUE |
|---|---|
| uzivatel:1 | pepa |
| uzivatel:2 | martin |
Relační
-
používá SQL - Structured Query Language, pro ovládání hodnot
-
sloupce - fields, řádky - fields #??
-
jednotlivé fields mají určený datový typ - int, string, datum…
-
vyžaduje schéma
-
relace - vyžaduje id u každého záznamu
- 1 ku 1
- to, co by mohlo být v jedné tabulce je ve 2 (druhá je navázána na první pomocí id v té první, každé id z první tabulky je v druhé jednou)
- v praxi zbytečné
- 1 ku n
- 1 hudební žánr hraje n kapel
- hudební žánr má id, to má u sebe každá kapela
- n ku n
- n kapel hraje n typů žánrů, jedna kapela hraje víc žánrů najednou
- pomocí propojovací tabulky
- v té jsou pouze 2 hodnoty - id žánru, id kapely
- 1 ku 1
-
je ACID komplicitní
- “protipól BASE”
- atomicity, consistency, isolation, durability
- prostě ať se posere cokoliv, vrátí ti přesně to, o co si žádal
- perfektní pro banky apod
-
nejpoužívanější typ databáze všude
-
software
- MySQL
- PHP
- MsSQL
- ASP.net
- PostgreSQL
- SQLite
- Microsoft Access
- MySQL
NoSQL
- “Not Only SQL”
- nepoužívá klasické tabulky, tabulkám se to však podobá
- škálují horizontálně
- pro zvýšení rychlosti serveru přidáváme další servery do clusteru
- opak s SQL databázemi
- šmíd - classa, která je v listu (jako třeba v C#)
- classa může mít různej shit, takže může každý field být rozdílný
- jednoduché NoSQL - vytvořit strukturu pomocí XML
- jazyk na ukládání dat podobný html
- ukázka:
<?xml version="1.0" encoding="UTF-8"?>
<trida>
<zak>
<jmeno>Josef</jmeno>
</zak>
<zak>
<jmeno>Martin</jmeno>
</zak>
<zak>
<jmeno>Jakub</jmeno>
</zak>
</trida>- ukázka 2 - JSON
- používané ve webových stránkách na přenos informací
{
}Wide column
-
výborný na analýzu dat
-
při správném navržení příšerně rychlý s velkým množství dat
-
jednotlivé tabulky nemají striktní hodnoty, které musíš vyplnit jako v SQL, každý záznam může mít jiné vlastnosti a některé vlastnosti můžeš prostě vynechat a nebude tam null nebo undefined, prostě nic (jedna ze všech vět světa tpč)
-
software
- cassandra
- apache hbase
Příklad - Cassandra
INSERT INTO posts (user_id, post_id, content, timestamp, photo_url)
VALUES (1001, p001, 'Dneska prší :(', toTimestamp(now()), 'https://pics.me/selfie.jpg');
Column family: users
| user_id | name | age | |
|---|---|---|---|
| 1001 | Karel | 23 | |
| 1002 | Anička | anicka@cool.cz | |
| 1003 | Boris | boris@swag.io | 31 |
Column family: posts
| user_id | post_id | content | timestamp | photo_url |
|---|---|---|---|---|
| 1001 | p001 | „Dneska prší :(“ | 2025-10-08T08:00 | https://pics.me/selfie.jpg |
| 1002 | p002 | „Miluju kafe ☕️“ | 2025-10-08T08:15 | |
| 1001 | p003 | „Nový projekt hotov!“ | 2025-10-08T10:00 |
{kind=link}
Dokument
- každý dokument obsahuje jeden key-value pair
- nestrukturovaný
- nevyžaduje schéma
- dokumenty jsou seskupené do kolekcí
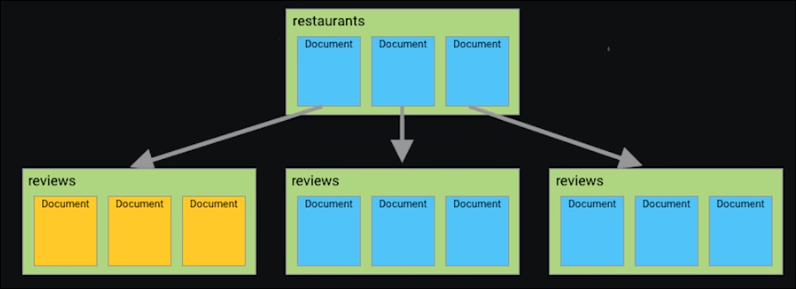
- trade-off - většinou je velmi rychlé sbírat data na zobrazení na frontendu, ale je mnohem pomalejší data zapisovat nebo přepisovat
- mnohem versatilnější než wide-columen nebo key-value
- špatný pro hodně provázané databáze (třeba facebook klon)
- software
- mongoDB
- firestore
- dynamoDB
- couchDB
Search engine
- vyhledávací software zpravidla používá strukturu podobnou dokumentové db
- search databáze si sama udělá index vyhledatelných hodnot (většinou slov)
- při vyhledávání hledá db v jejím indexu a ne v user-created databázi
Grafová
- přímo spojuje data, která k sobě patří
- nevyžaduje extra spojovací tabulku jako relacionální tabulky
- software
- neo4j
- Dgraph
Multi-model
- existují databázové softwary, kterým naházíš, co chceš ukládat a jak k tomu chceš přistupovat, a on si sám vymyslí, jestli a kde použije Graph, Dokument, nebo Relacionální databázi na daný kus dat
- míchá tyhle tři mezi sebou
- perfektní na ohromný code báze se spoustou dat na porovnání
- software - FaunaDB
- o tomhle beztak Šmíd ani neslyšel xd
CAP theorem (Brewer’s theorem)
- když je několik serverů v clusteru
- říká, že jakékoliv distribuované data mohou v případě výpadku zajistit pouze 2 z těchto 3 záruk
- záruky:
- Konzistence (Consistency - C)
- každá operace získává nejnovější data, nebo navrací error
- každá operace čtení čte nejnovější zápis, nebo navrací error - 2 různý definice, vyjadřující to samý abych dostal ten point across
- Dostupnost (Availability - A)
- každý požadavek získává úspěšnou odpověď, bez garance inkluze nejnovějších dat
- Tolerance oddílů (Partition Tolerance - P)
- systém pokračuje ve fungování, i když selže komunikace mezi jednotlivými databázemi
- Konzistence (Consistency - C)
- v realitě nejde nemít toleranci oddílů když jsou data na několika serverech
- CA je teoreticky jeden samostatný databázový server, pokud ignorujeme výpadky sítě na tom jednom serveru
- CP - Jeden server se určí jako hlavní, v moment výpadku vedlejší servery nepřijímají žádná data a veškerá komunikace je možná jenom s hlavním serverem, aby se předešlo konfliktům dat
- při výpadku komunikace - pouze hlavní server přijímá zápisy, vedlejší server nepřijímá vůbec nic, většinou odesílá “not available”, ale závisí na implementaci
- v praxi - banky. když vypadne vedlejší server, není možný, aby byl rozdílný zůstatek na účtu na různých serverech. server prostě odmítne odpovědět, protože neví, jestli má aktuální data
- AP - systém odpoví vždy, i za cenu, že data nejsou úplně přesná. konflikty se musí řešit po návratu sítě do normálního pochodu.
- při výpadku komunikace - oba servery přijímají zápisy
- v praxi - sociální sítě. nikoho nezajímá, že se zrovna nepřipočítali 4 liky z vedlejšího serveru, hlavní je, že server odpověděl a ta odpověď dávala smysl
Šmíd trick questions
- jaký je nejjednodušší způsob udělání databáze
- jaký je rozdíl mezi HTML a XML